General presentation of the BRAID-Acq model
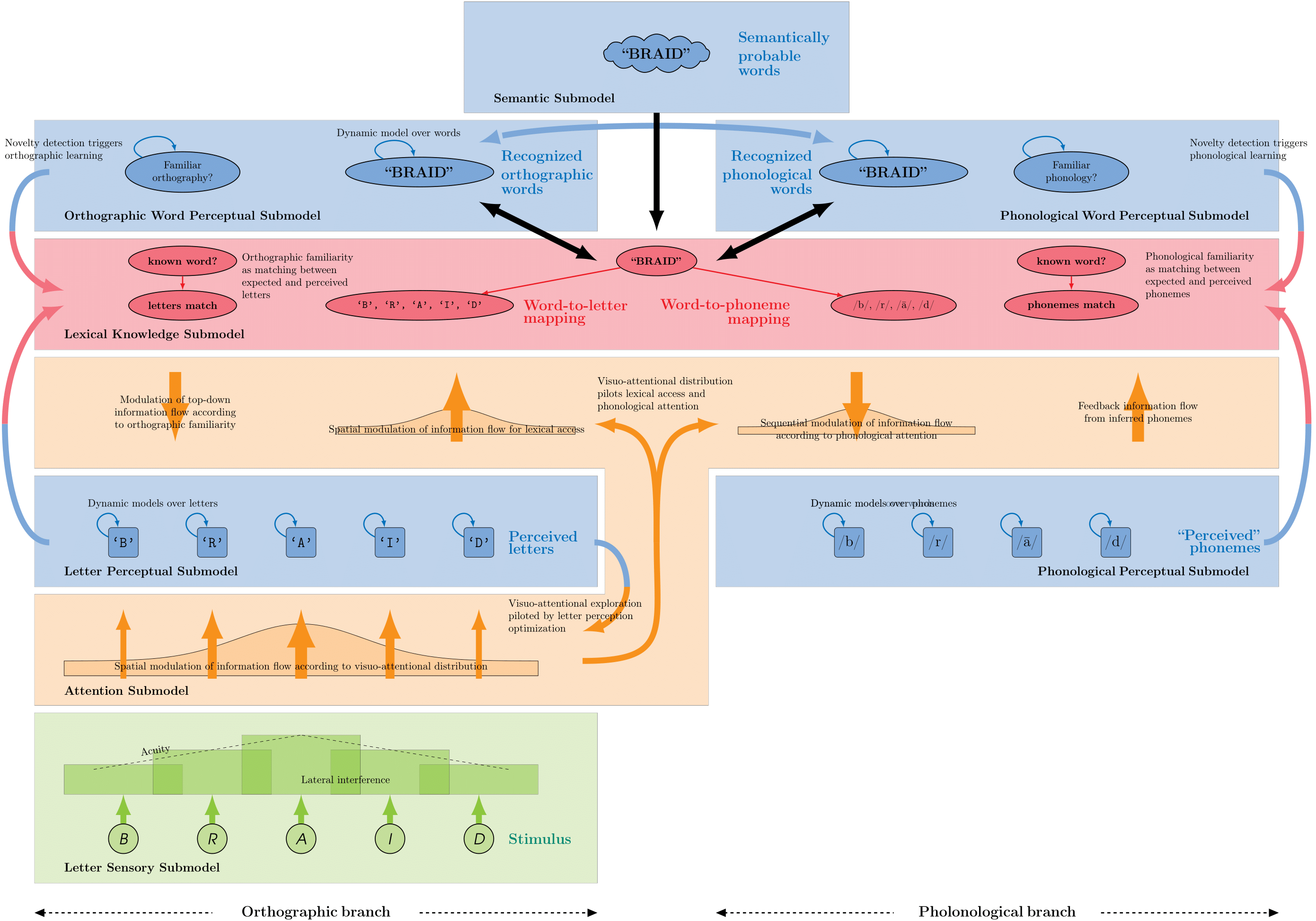
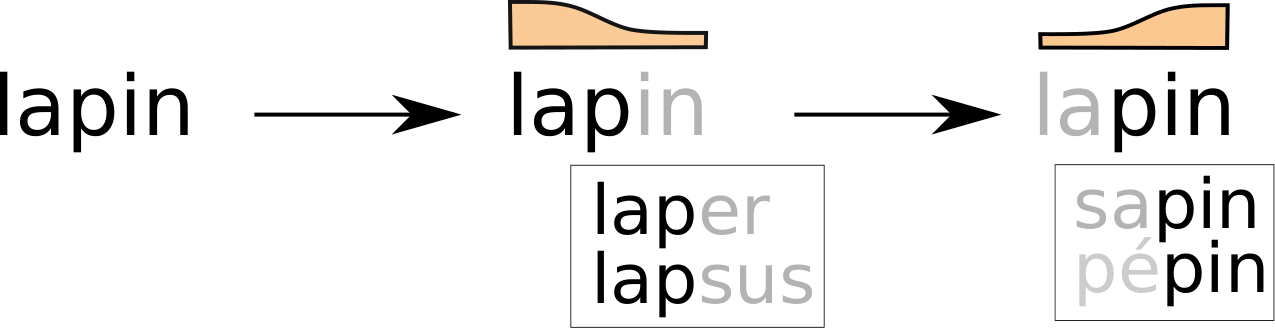
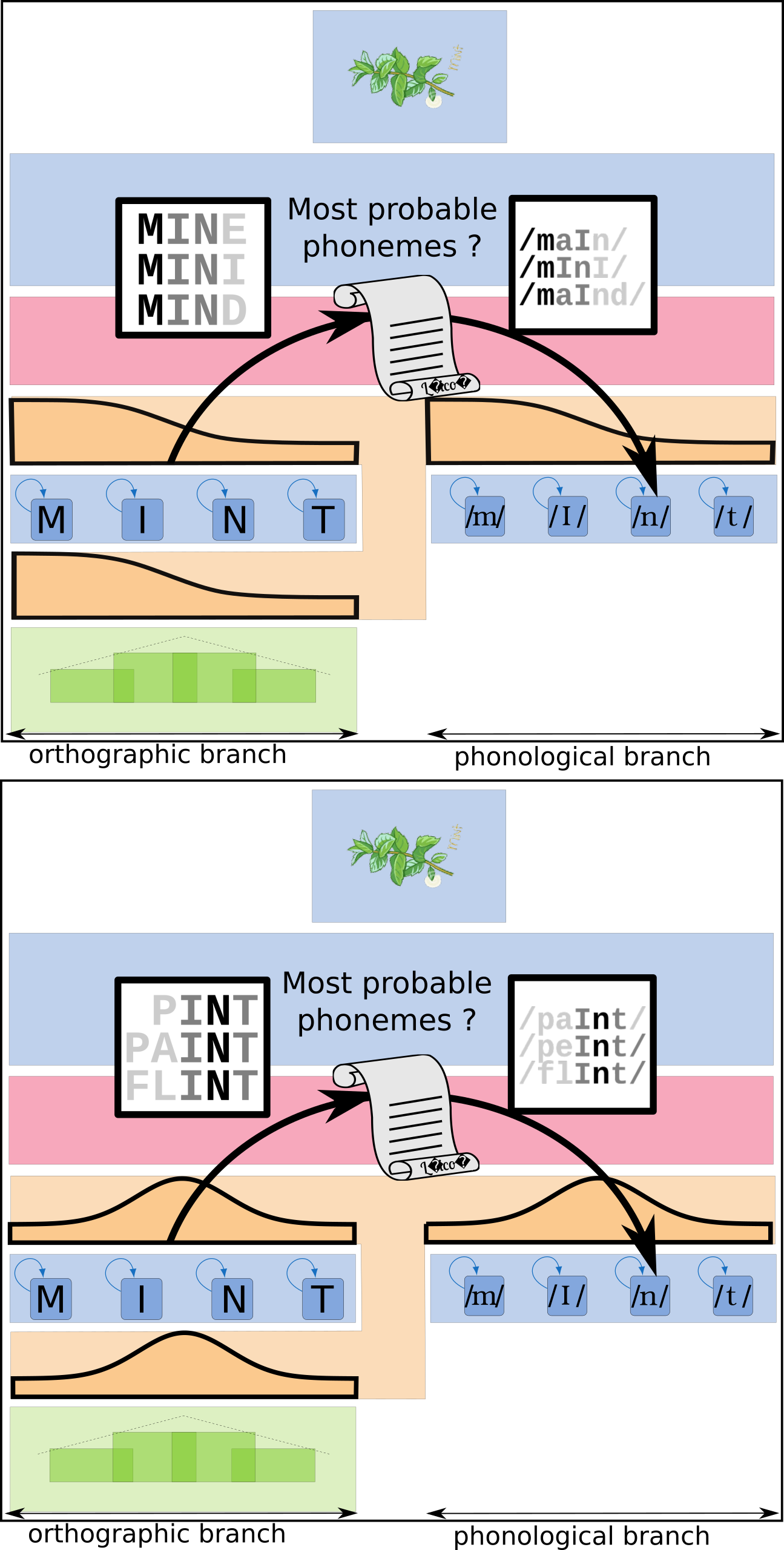
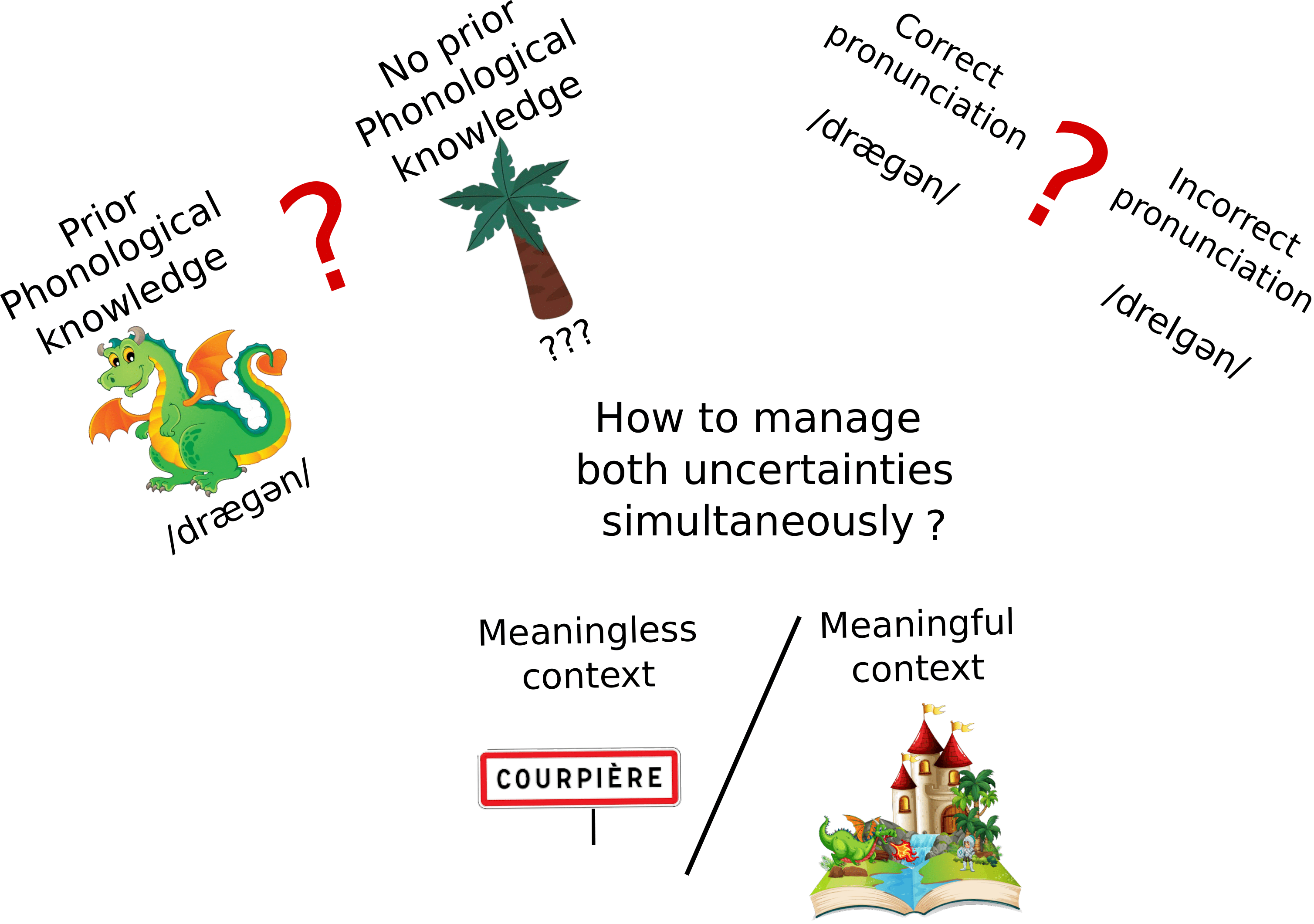
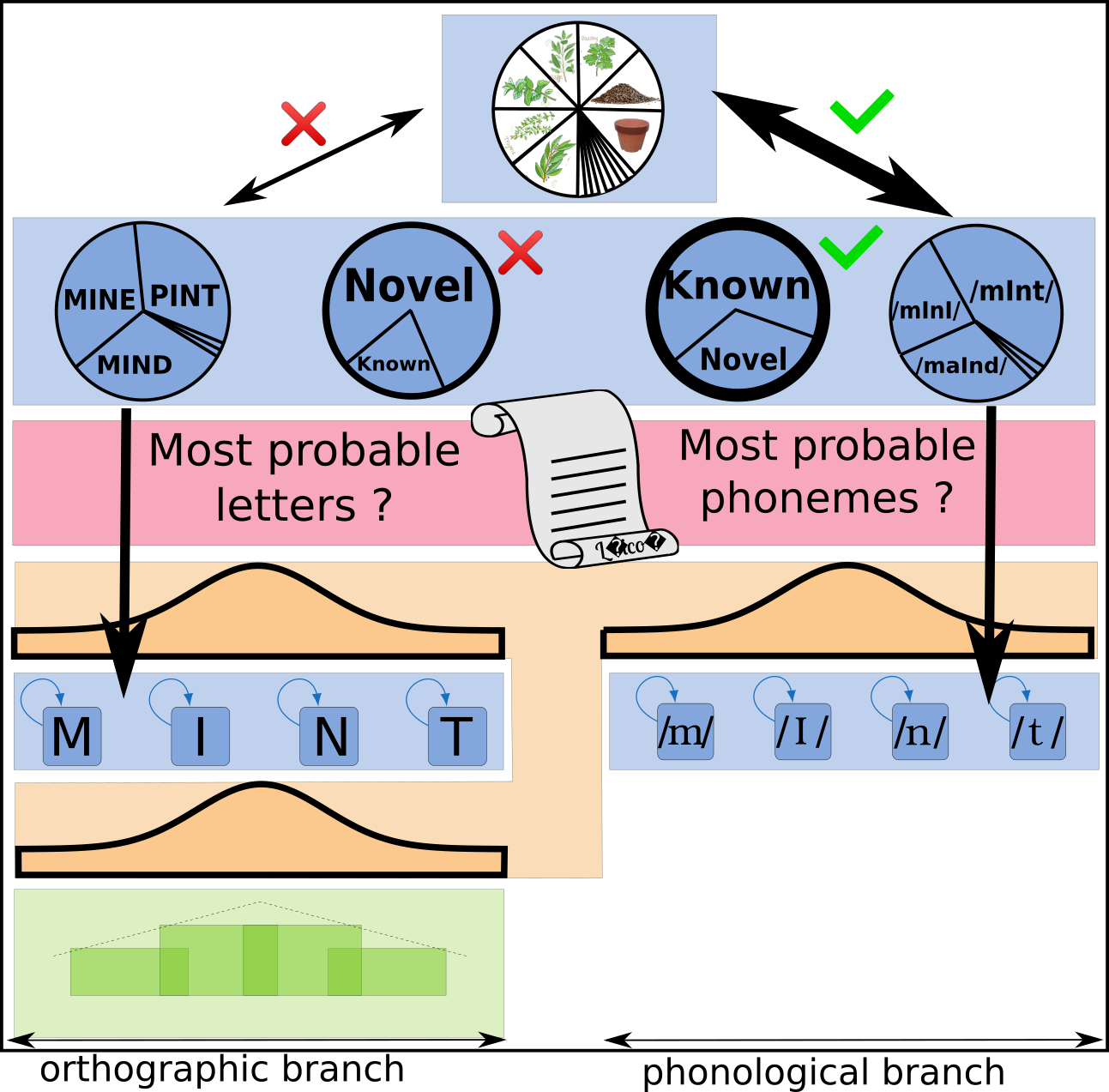
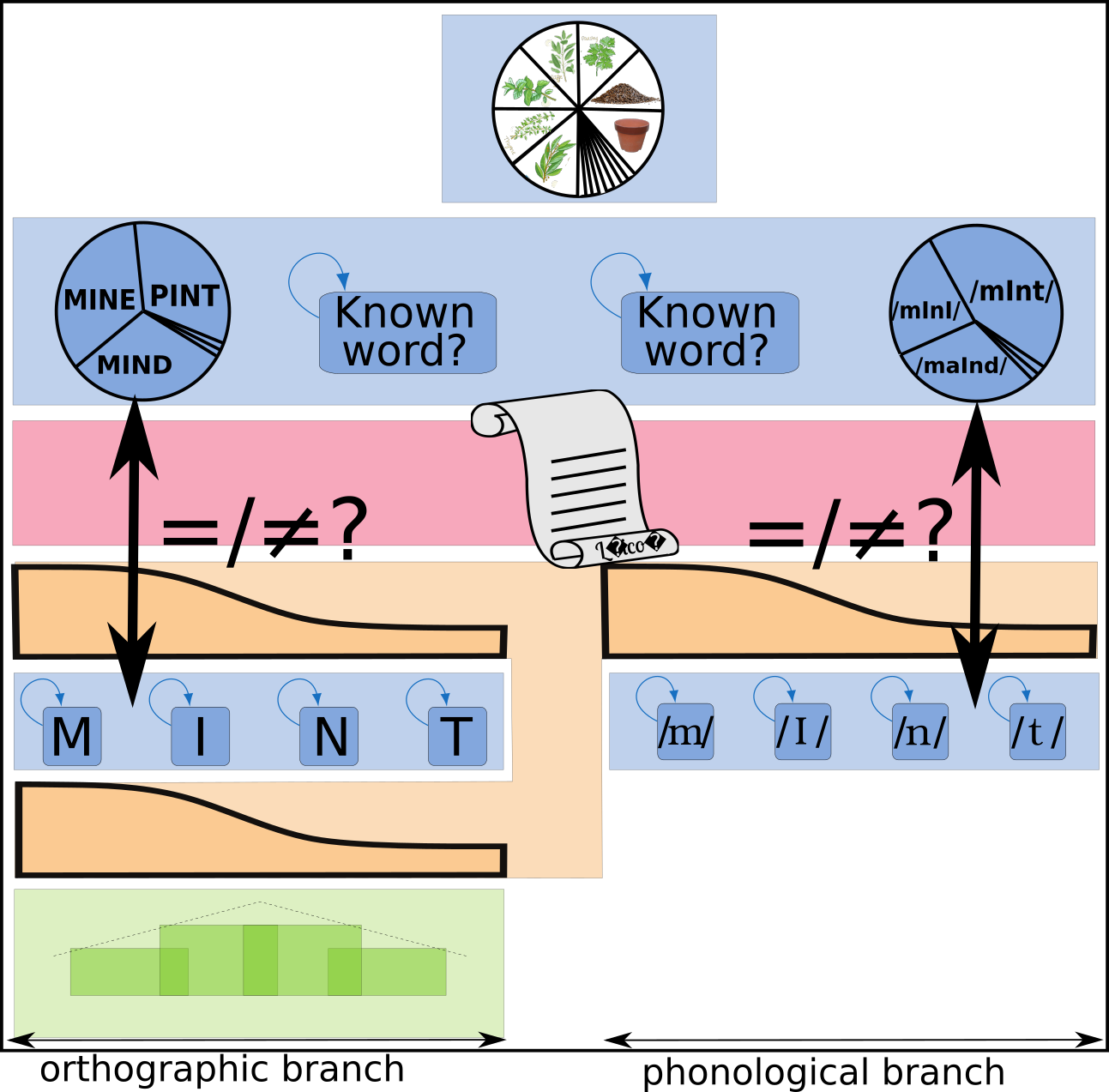
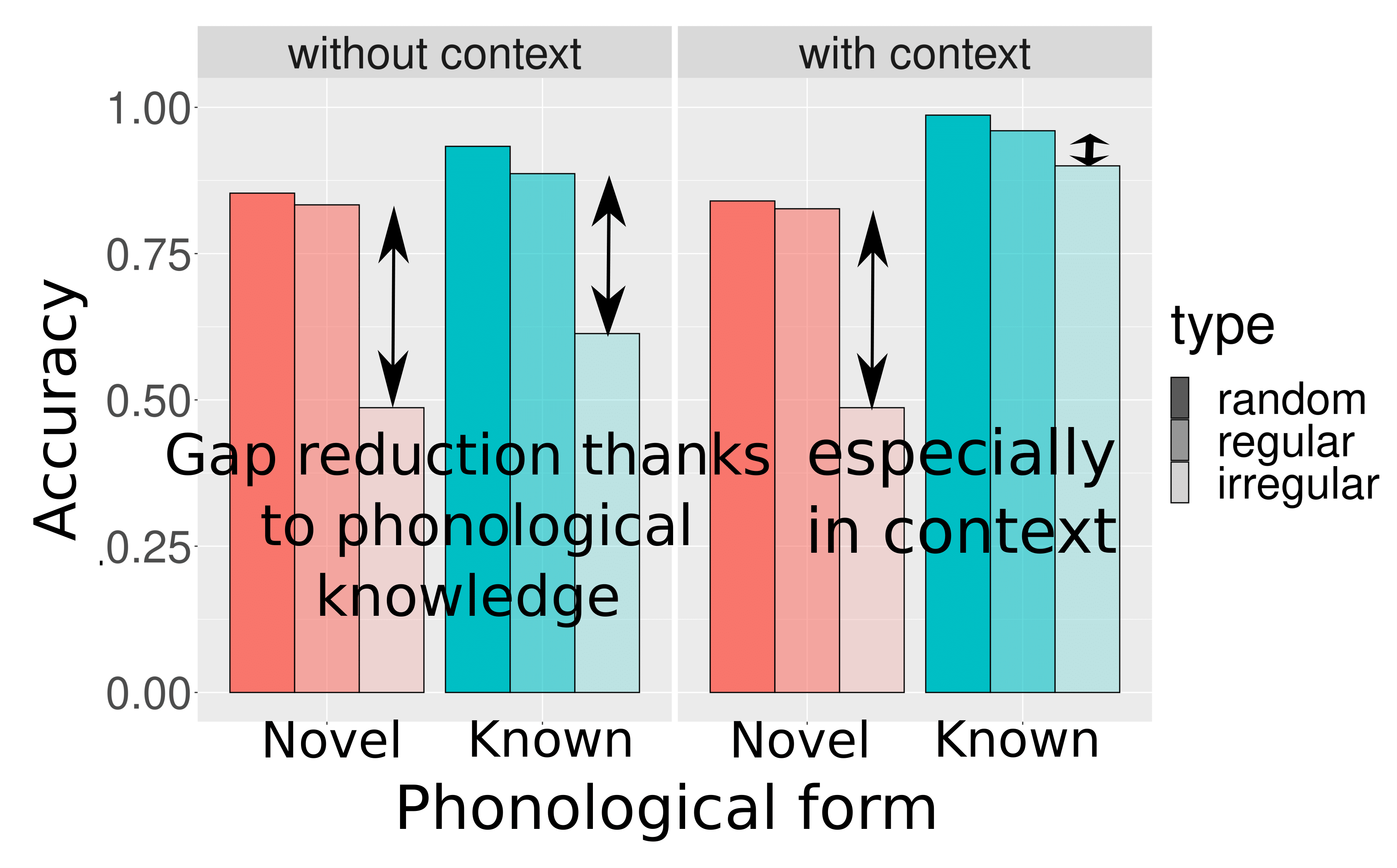
The BRAID-Acq model is a probabilistic computational model of self-teaching and reading acquisition that simulates incidental orthographic learning tasks. It is based on a single-route architecture that is able to read both known and novel words using an analogy-based procedure, relying solely on lexical knowledge, without featuring grapheme-to-phoneme conversions. This reading procedure is enabled by a visuo-attentional sub-model that gathers visual information without aligning to predefined psycholinguistic units. Its exploration mechanism simulates the successive positions of the model by maximizing the intake of visual and phonological information, rather than processing each grapheme individually. Additionally, a phonological attentional sub-model, coupled with the visual counterpart, roughly aligns orthographic and phonological positions without relying on graphemic segmentation of the word. Its extended learning mechanism allows it to acquire and update both orthographic and phonological lexical knowledge. Finally, the model integrates a simplified representation of semantic context: the context favors the identification of certain words throughout the entire processing and enables the correction of pronunciation for phonologically familiar words, without compromising the pronunciation of phonologically unfamiliar words (pseudo-words). The source code of the BRAID-Acq model is available here, and my thesis manuscript in French is available here.