Other research : topics of interest
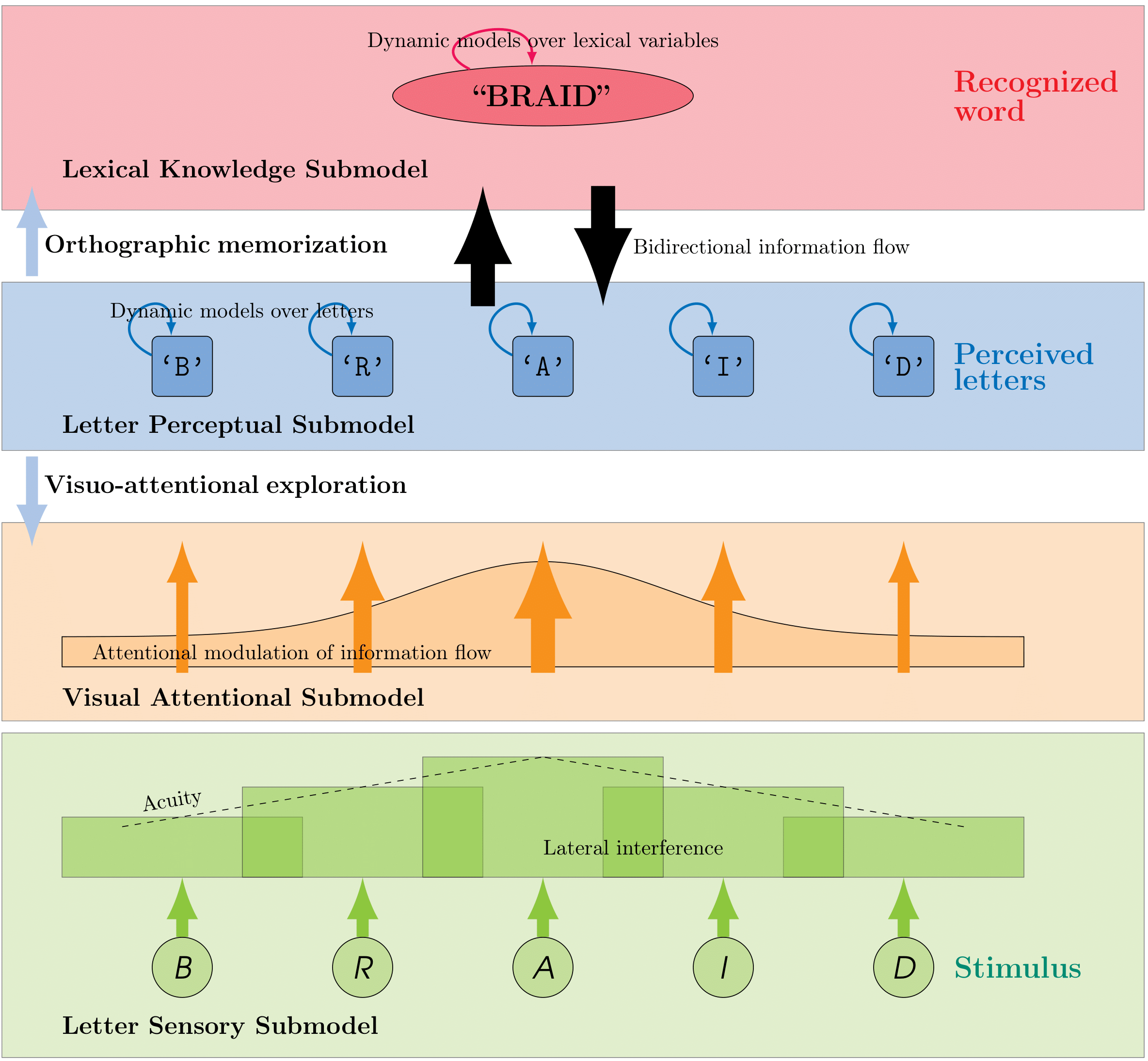
The BRAID-Learn model
During my PhD, I used the BRAID-Learn model, a probabilistic computational model of orthographic learning, to explore how visuo-attentional resources affect incidental orthographic learning. BRAID-Learn includes mechanisms for detecting novelty, updating orthographic traces, and a visual-attentional exploration algorithm that optimizes the accumulation of perceptual evidence during processing. This model successfully explained the evolution of eye movement trajectories observed during the incidental learning of new words in expert readers over successive presentations. Using this model, I showed that, contrary to popular belief, it's possible to simulate the length effect for novel words with a purely visual model, and that reduced attentional resources can amplify this effect. Additionally, I found that orthographic learning acts as a compensatory mechanism when attentional resources are limited. This work has been published in Vision Research, and the source code for the BRAID-Learn model is available here.
Pseudo-Word generation
During my master's thesis, I developed an algorithm to generate spoken pseudo-words in French and German, as no cross-linguistic tools were available for this purpose at the time, and we wanted to define our own custom linguistic constraints. It starts by randomly generating a large number of words in the two most frequent schemes in German (CVC and CVCV), based on syllable frequency. From these, a subset is selected according to phonotactic probabilities, maximizing the positional frequency of phonemes and biphones, and ensuring legal sequences of triphones. We then applied a selection based on the distance to the lexicon. A lower distance to the lexicon indicates the presence of a neighbor, which could cause interference during processing, while a greater distance means the pseudo-word does not resemble any word in the lexicon and could therefore be non-wordlike. For more realism, a custom measure of distance between phonemes was used, adapting the classical Levenshtein distance to incorporate articulation constraints. This set of pseudo-words is then ready for use! The source code is available here.

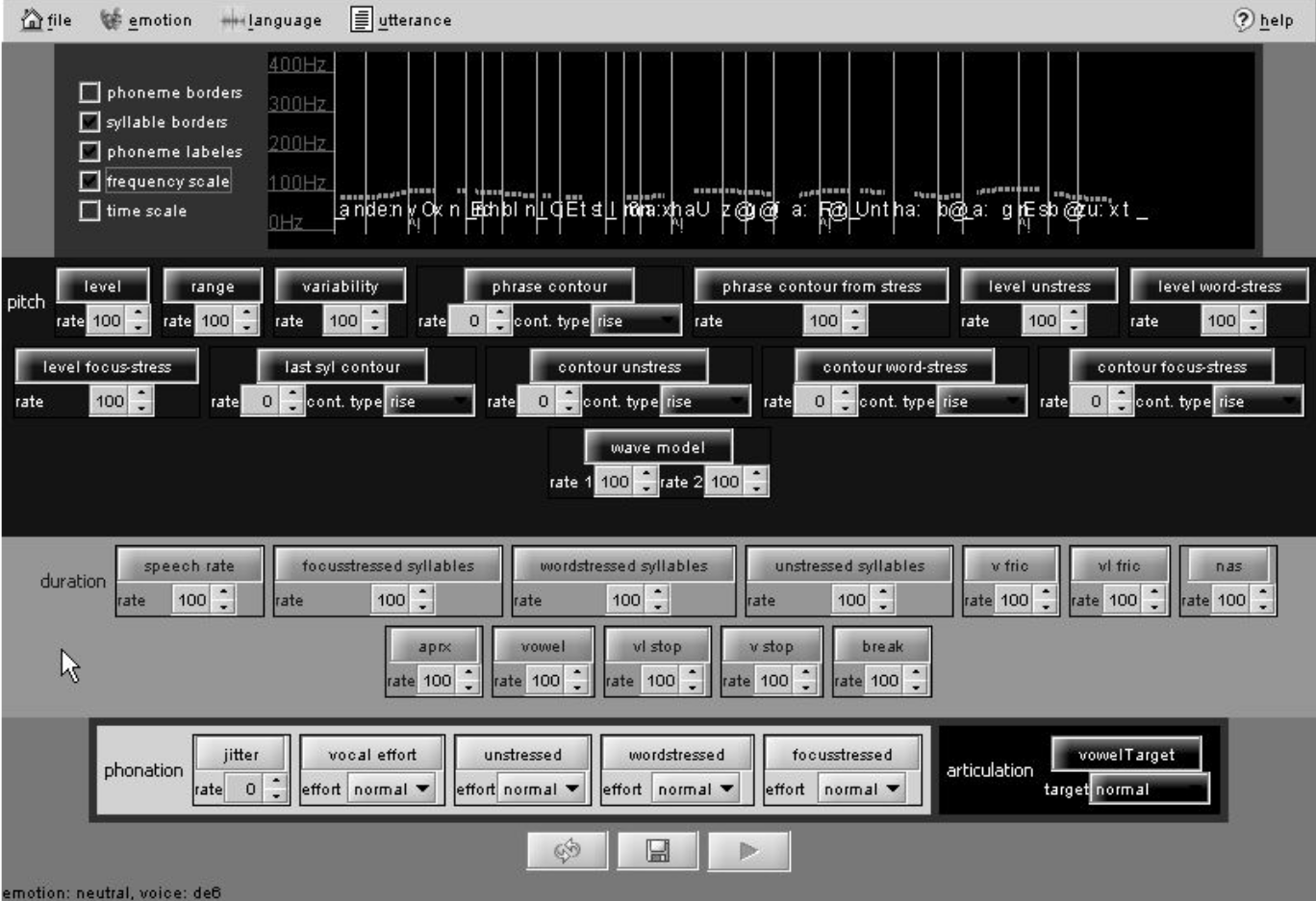
Detecting irony in speech
During my time at Deutsche Telekom, I used Emofilt, a software program designed to simulate emotional arousal in speech synthesis, to evaluate purely acoustic strategies for generating ironic speech. Specific acoustic features were extracted as potential candidates for creating irony in speech, such as exaggerated articulation, over-stressing focus syllables, pitch modulation, and low arousal. These strategies were applied to German sentences with varying levels of inherent irony (inherently ironic or positive). The resulting synthesized stimuli were evaluated by native German listeners in a perception experiment. The results showed that all four strategies used to signal irony in speech synthesis—exaggerated articulation, over-stressing focus syllables, pitch modulation at the end of sentences, and speaking with low arousal—were preferred over the default versions. This work has been published here., and the code of the Emofilt software is available here.